


2. Overall Data Architecture and Layering
A new generation of Industry 5.0 EAM platforms is no longer just CRUD-style SaaS software. It is a system designed to turn operational data into decision-ready data assets.
Traditional EAM systems were, at their core, workflow systems: asset registration, work order routing, failure logging, and spare parts movement. Data mainly existed to support business operations.
But in the context of Industry 5.0, what enterprises truly care about is no longer just “recording what happened.” They care about questions like:
- When is a machine likely to fail?
- Is the current maintenance strategy really optimal?
- Is reliability improving over time?
- Can the data support prediction and optimization?
This means an EAM platform must evolve from a System of Record into a System of Intelligence.
And the foundation of that transition is not the UI, and not even the AI model itself. It is the data architecture.
Many teams instinctively jump to “build AI” or “upgrade the interface.” In practice, the opposite is true: even the most powerful AI cannot make reliable decisions on top of chaotic data.
The prerequisite for intelligence is not the model. It is:
a data architecture with clear structure, strict boundaries, and stable semantics.
2.1 Why Layering Is Necessary: Complexity Does Not Merely Grow — It Mutates
As EAM SaaS platforms evolve, one lesson becomes clear:
When the data footprint is still small, layering can feel like an aesthetic choice. But once multi-tenant onboarding, real-time data growth, analytics, and AI requirements begin to compound, a system without explicit boundaries quickly becomes unmanageable.
We did not start with a six-layer architecture on day one. This structure was not invented in abstraction. It was forced out of us by the realities of scale and system complexity.
A typical failure path looks something like this:
- Once the ingestion layer starts doing business transformations, semantic drift appears almost immediately: the same field begins to mean different things in different pipelines.
- Once the streaming layer takes on modeling responsibilities, it turns into a black box: logic becomes hard to audit, replay, or debug.
- Once the warehouse is directly exposed to front-end applications or end users, cost and access control spiral out of control: queries become unpredictable and compute usage becomes difficult to govern.
- Once AI bypasses the semantic layer and reads raw data directly, metrics lose meaning: predictions cannot be reproduced and business definitions fall apart.
These issues all share the same root cause:
The system was never forced into layers, so responsibility boundaries remained vague, and eventually every part of the stack could do everything.
That is why we ultimately split the EAM SaaS data platform into six explicit layers and defined strict responsibilities for each of them.
2.2 The Six-Layer Architecture: Defining System Boundaries Through Data Flow
We use a six-layer model that can be implemented in real engineering environments:
| Layer | System Role | One-Line Definition |
|---|---|---|
| Ingestion | Data entry layer | Captures data from the real world |
| Streaming | Event flow control layer | Keeps change moving in a stable way |
| Lake | System memory layer | Preserves replayable history |
| Warehouse | Semantic modeling layer | Standardizes definitions and builds business semantics |
| Serving | Data delivery layer | Exposes data externally in a controlled manner |
| AI | Intelligence enhancement layer | Performs prediction and reasoning on top of semantics |
Layering is not about elegance. It is about control.
Each layer must answer two questions:
- What am I responsible for?
- What am I explicitly not responsible for?
2.3 Responsibility Boundaries: Each Layer Should Do One Thing Well
| Layer | Core Responsibilities | Explicitly Out of Scope |
|---|---|---|
| Ingestion | Ingest data from multiple sources; attach standard metadata; preserve raw records | No semantic transformation; no metric computation |
| Streaming | Decouple producers and consumers; absorb spikes; support replay | No long-term history; no modeling |
| Lake | Immutable storage; partition by tenant/time; support replay | No low-latency serving |
| Warehouse | Standardize units; integrate master data; compute metrics | No raw exposure; no flow control |
| Serving | Provide APIs / BI views; caching and access control | No modification of source facts |
| AI | Feature construction; vectorization; prediction and recommendation | No direct reads from raw data outside the semantic layer |
In practice, what makes a system stable over time is not how strong any single layer is. It is whether each layer actually respects its boundary.
2.4 The Current EAM SaaS Data Platform in Practice
This layered model is not just a conceptual diagram. We have implemented it as a working engineering architecture.
From the perspective of data movement, the flow is straightforward:
Sources → Ingestion → Streaming → Lake/Warehouse → Serving → AI
A unified orchestration layer runs across the entire chain.
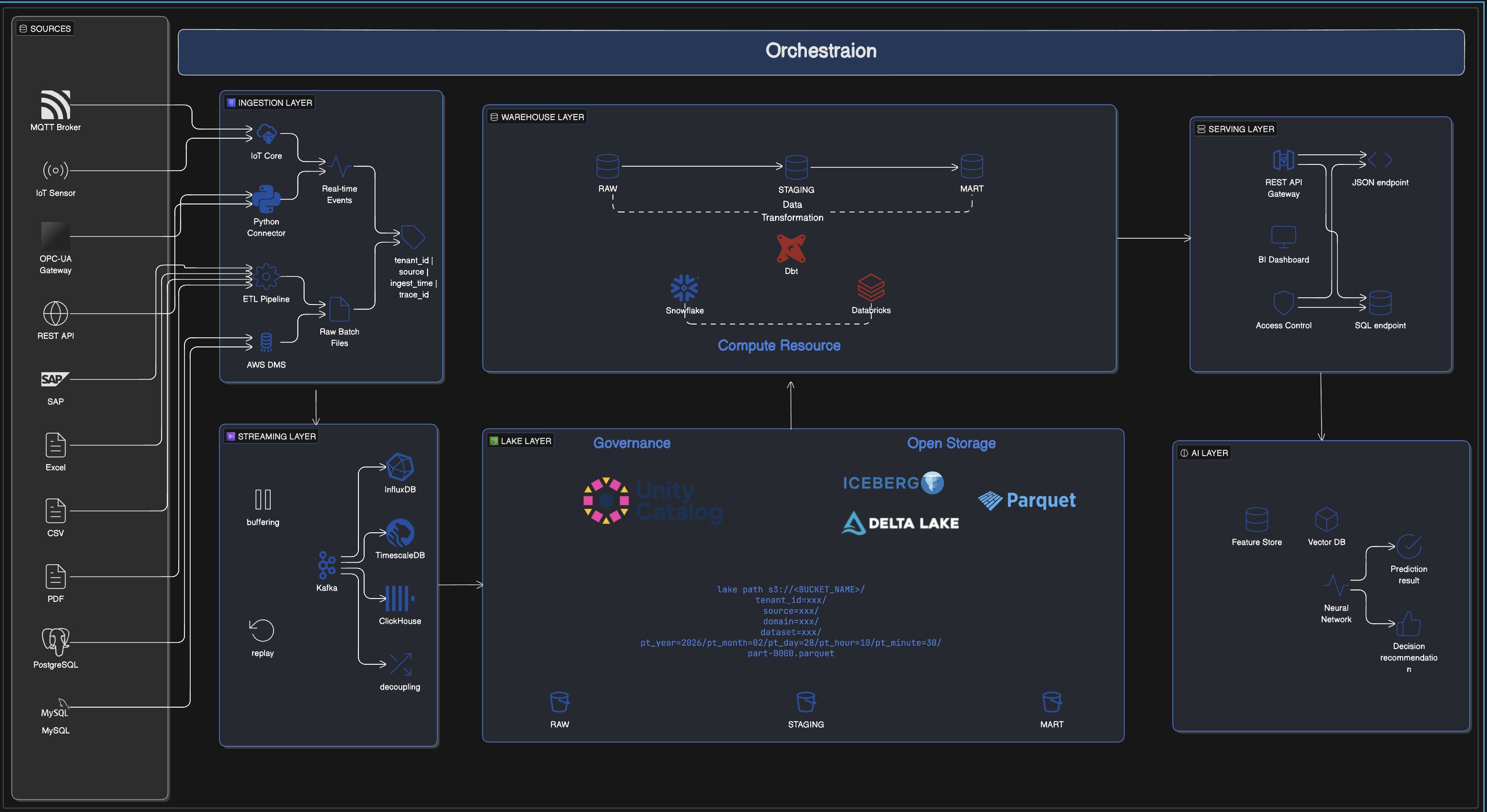
The real value of this chain is not that it contains many layers. It is that it turns previously blurry responsibilities into clear boundaries that can be implemented, governed, and scaled.
2.5 Sources: Where the Data Comes From
An EAM SaaS platform does not ingest data from a single database. It ingests from the mixed reality of industrial environments:
- Real-time signals: MQTT / IoT Sensors / OPC-UA / Historian
- Business systems: PostgreSQL / MySQL / SAP / REST API
- Unstructured files: Excel / CSV / PDF (SOPs, manuals, reports)
These sources are inherently heterogeneous. They operate at different tempos and vary widely in quality. That is exactly why layering is necessary: industrial data is not “one database”; it is an ecosystem.
2.6 Ingestion: Bring the Data In and Standardize the Context — Do Not Interpret the Business
In the EAM SaaS data platform, the ingestion layer is responsible for exactly one thing:
Bring data into the platform reliably and attach a standard context to it.
This goal sounds modest, but it is foundational:
- Data must be ingested reliably
- Data must be traceable
- Data must be isolatable
- Data must be replayable
So regardless of whether the data comes from real-time devices or batch-oriented systems, the platform appends a standard set of metadata at ingestion time, such as:
tenant_id: the root of tenant isolation and cost attributionsource: the source system, protocol, or connector identifieringest_time: the time the data entered the platform, not the business event timetrace_id: used for cross-layer tracing and auditability
These fields do not express business meaning. They express the data’s identity and context.
2.6.1 Two Ingestion Paths: Real-time Events and Raw Batch Files
Within EAM SaaS, ingestion splits data into two paths.
A) Real-time Data: Real-time Events
For IoT and sensor events, we use IoT Core + Python Connector to push data into the real-time event channel, ensuring that:
- data enters the platform as an event stream,
- it can be consumed by the streaming layer in a decoupled way,
- each event carries the same standard context metadata.
B) Batch Data: Raw Batch Files
For traditional business systems such as SAP, database CDC, or REST API extraction, we use ETL pipelines / AWS DMS to generate raw batch files and land them in a staging area, ensuring that:
- data lands as immutable files,
- it can be replayed and recomputed by the lake and warehouse layers,
- business logic is not pushed into ingestion.
2.6.2 The Core Principle of Ingestion: Do Not Interpret Business Meaning
The ingestion layer must stay intentionally restrained:
- no business semantic transformation (for example, status remapping or business definition correction),
- no metric computation (such as MTBF, OEE, or Availability),
- no cross-source joins (such as merging equipment, work order, and spare parts data).
The reason is simple:
The “smarter” ingestion becomes, the less controllable the system becomes.
The earlier semantics appear, the earlier semantic fragmentation begins.
Semantics should be modeled centrally in the warehouse — not inferred independently by each connector.
2.7 The Industrial IoT Exception: Why Ingestion Must Perform Asset/Tag Mapping
In industrial IoT scenarios, adding generic metadata alone is not enough.
In reality, the identifiers coming from field devices are deeply tied to protocols, vendors, and project conventions. For example:
- MQTT topic:
factory/line1/motorA/vibration - OPC-UA NodeId:
ns=2;s=Channel1.Device3.Tag99 - Historian tag:
PUMP_01_TEMP_PV - custom sensor code:
S-39201-AXX
These identifiers may uniquely point to a measurement point, but they are not the same thing as the platform’s standard asset semantics. If downstream systems need to query telemetry by asset, they must first answer two questions:
- Which asset does this telemetry belong to (
asset_id)? - Which measurement point on that asset does it represent (
tag_id)?
That is why we perform a basic mapping step during ingestion:
- parse a measurement identifier from the raw sensor code, topic, or OPC-UA NodeId,
- map that identifier to a standardized
tag_id, - bind it to a normalized
asset_id.
2.7.1 This Is Not Business Modeling — It Is Alignment Engineering
This distinction is important:
This is not business modeling in the ingestion layer, and it is certainly not metric computation.
Its role is simply to establish a shared reference system for everything that comes later.
It solves some of the most practical pain points in industrial data:
- different protocols use different naming schemes,
- the same point may have different names across systems,
- the same asset may use different codes across plants or projects.
Without this basic mapping, downstream systems quickly run into real problems:
- time-series data cannot be aligned with asset master data,
- signals from the same machine may be treated as separate assets,
- queries depend on guessing topic or tag names,
- AI features become unstable and training cannot remain consistent with inference.
In other words:
You can standardize business definitions later in the warehouse,
but you must standardize identity first in ingestion.
2.7.2 Recommended Mapping Outputs
In practice, we usually materialize two kinds of outputs here. We only introduce the concepts here and leave the implementation details for Part 03.
A) Mapping Table (Mapping Registry)
Used to map external identifiers to standardized platform identifiers:
source_type(mqtt / opcua / historian / …)source_identifier(topic / nodeId / tag_name / …)asset_idtag_ideffective_from/effective_to(to support equipment modification and point migration)version(to support change auditing)
B) Standard Event Fields (Normalized Event Envelope)
Before a real-time event enters the streaming layer, it should contain at least the following fields:
tenant_idasset_idtag_idevent_time(device time / collection time)ingest_time(platform entry time)valuequality(optional)
A typical JSON payload may look like this:
1 | { |
With this normalized event envelope, downstream systems no longer need to understand the differences between underlying industrial protocols in order to consume real-time data consistently.
2.8 Summary: The Purpose of Layering Is to Let the System Grow Without Losing Control
Splitting the EAM SaaS data platform into six layers is, at its core, about one thing:
using boundaries to control complexity.
Once the system begins to scale, layering is not a matter of style. It becomes a condition for survival.
- Without restraint in ingestion, there is no semantic consistency.
- Without decoupling in streaming, there is no stable real-time pipeline.
- Without immutable history in the lake, there is no replayability or auditability.
- Without unified modeling in the warehouse, there are no reliable metrics and no explainability.
- Without controlled delivery in serving, there is no governance over cost, permissions, or external SLAs.
- Without AI depending on the semantic layer, there are no reproducible predictions or decisions.
If an Industry 5.0 EAM platform is going to become a true system of intelligence, it must first become a system of data order.
