


二、整体数据架构与分层
面向工业 5.0 的新一代 EAM 智能平台,早已不再是简单的 CRUD 型 SaaS 软件,而是帮助企业将数据沉淀为可决策的数据资产(Decision-ready Data Assets)。
过去的 EAM 系统,本质上是流程系统:资产建档、工单流转、故障记录、备件出入库。数据存在的主要目的,是支撑业务操作本身。
但在工业 5.0 的语境下,企业真正关心的,已经不只是“记录发生了什么”,而是:
- 设备什么时候会出问题?
- 当前维护策略是否最优?
- 可靠性是否在持续提升?
- 数据是否能够支撑预测与优化?
这意味着,EAM 平台必须从“记录系统(System of Record)”升级为“认知系统(System of Intelligence)”。
而这个转变的核心,不是 UI,不是 AI 模型,而是数据架构。
很多人第一反应是“做 AI”或“升级界面”。但事实恰恰相反:哪怕是最强大的 AI,也无法在混乱的数据之上建立可靠判断。
认知能力的前提,从来不是模型本身,而是:
结构清晰、边界分明、语义稳定的数据架构。
2.1 为什么必须分层:复杂度不是“放大”,而是“变质”
在 EAM SaaS 的演进过程中,我们逐渐意识到一个问题:
当数据规模还小时,分层看起来更像一种“结构美学”;但当多租户接入、实时数据增长、分析与 AI 需求叠加之后,如果系统没有明确边界,复杂度不会只是线性放大,而是会发生本质性的“变质”。
我们并不是一开始就设计出六层架构。相反,这套结构是在系统复杂度不断上升的过程中,被现实问题一步步“逼”出来的。
典型的失控路径通常是这样的:
- 采集层一旦开始做业务转换,很快就会出现语义分裂:同一个字段在不同接入链路中含义不同。
- Streaming 层一旦承担建模职责,就会逐渐演变成难以维护的黑盒:逻辑不可审计、不可回放、难以排错。
- Warehouse 层如果直接暴露给前端或业务方,成本与权限很快就会失控:查询不可控、算力不可预测。
- AI 层如果绕过语义层直接读取 raw 数据,指标口径就无法解释:预测结果无法复现,分析结论无法对齐。
这些问题背后的共同根因只有一个:
系统没有被强制分层,职责边界不清晰,最终导致“任何地方都可以做任何事”。
于是,我们最终将 EAM SaaS 的数据平台明确拆分为六个层级,并为每一层强制定义职责边界。
2.2 六层架构:从数据流动视角定义系统边界
我们采用一套可以工程化落地的六层划分方式:
| Layer | 系统角色 | 一句话定位 |
|---|---|---|
| Ingestion | 数据入口层 | 记录现实世界的数据 |
| Streaming | 事件流控制层 | 让变化稳定流动 |
| Lake | 系统记忆层 | 保存可重放的历史 |
| Warehouse | 语义建模层 | 统一口径,构建业务语义 |
| Serving | 数据交付层 | 以可控方式对外提供数据 |
| AI | 认知增强层 | 基于语义进行预测与推理 |
分层不是为了好看,而是为了可控。
每一层都必须回答两个问题:
- 我负责什么?
- 我明确不做什么?
2.3 职责边界:每层“只做一件事”,并且做得足够好
| Layer | 核心职责 | 明确不做什么 |
|---|---|---|
| Ingestion | 接入多源数据;附加统一元数据;保留原始记录 | 不做语义转换;不计算指标 |
| Streaming | 解耦生产消费;削峰填谷;支持回放 | 不沉淀长期历史;不建模 |
| Lake | Immutable 存储;按 tenant/time 分区;支持 replay | 不提供低延迟服务 |
| Warehouse | 单位统一;主数据整合;指标计算 | 不暴露 raw;不承担流控 |
| Serving | 提供 API / BI 视图;缓存与权限控制 | 不修改底层事实 |
| AI | 特征构建;向量化;预测与推荐 | 不绕过语义层读取原始数据 |
从工程实践来看,真正让系统长期稳定演进的,并不是某一层本身有多强,而是各层是否真的守住了边界。
2.4 EAM SaaS 当前的数据平台实现(工程落地)
上面的分层并不是一个停留在 PPT 上的概念模型,我们已经将其落成了一套可以持续运行的工程化架构。
从数据流动角度看,它对应的是一条清晰的链路:
Sources → Ingestion → Streaming → Lake/Warehouse → Serving → AI
并由统一的 Orchestration 贯穿全链路。
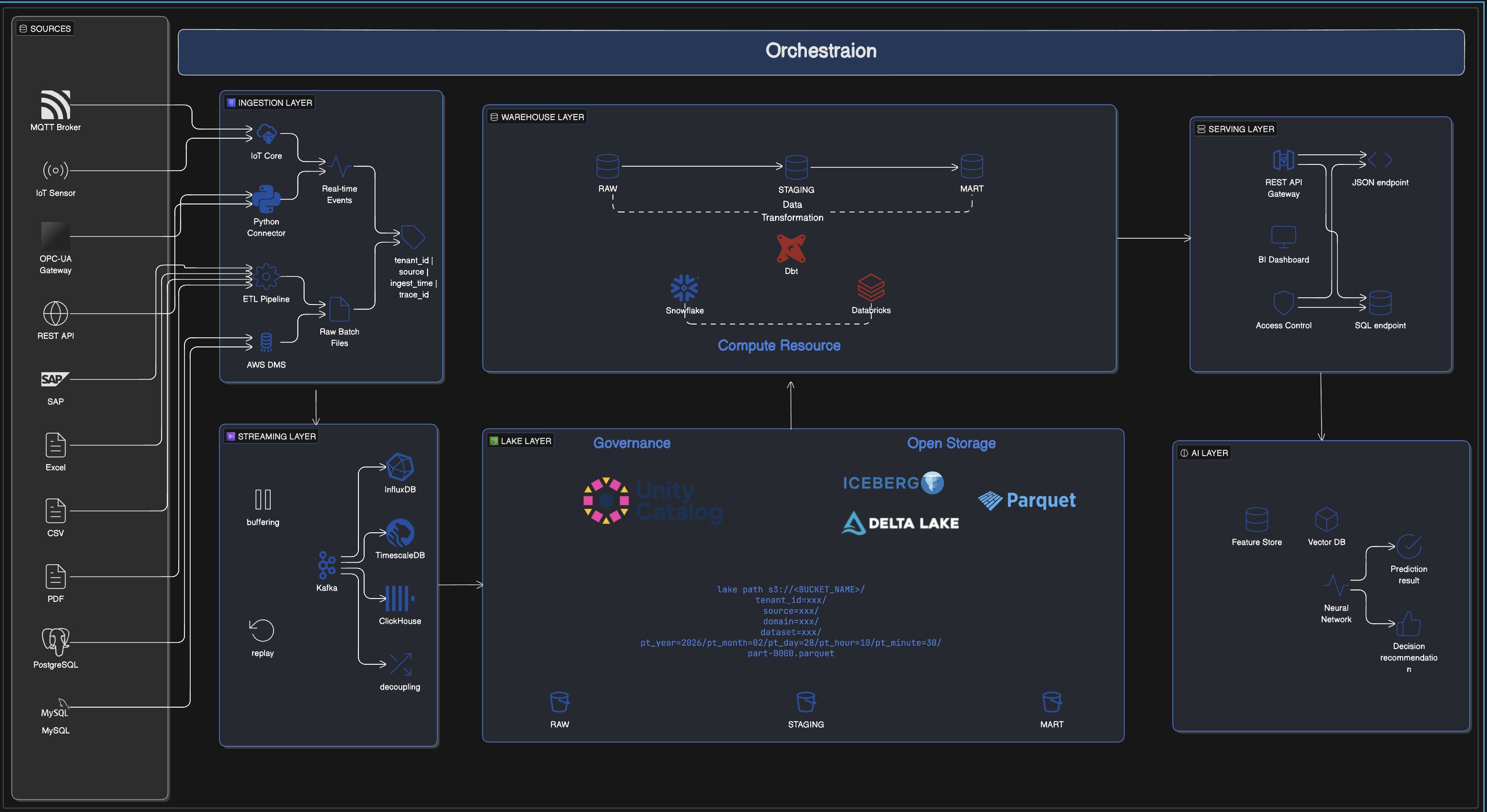
这条链路的重要意义,不在于“层数够多”,而在于它将复杂系统中原本模糊的职责拆成了一组可以被实现、被治理、被扩展的清晰边界。
2.5 Sources:数据从哪里来(工业现场的真实复杂性)
EAM SaaS 接入的并不是单一业务库,而是典型工业现场中的“混合数据源”:
- 实时信号:MQTT / IoT Sensor / OPC-UA / Historian
- 业务系统:PostgreSQL / MySQL / SAP / REST API
- 非结构化文件:Excel / CSV / PDF(SOP、手册、报告)
这些数据源天然异构、更新节奏不同、质量参差不齐。
这也是我们必须坚持分层的根本原因:工业数据不是“一个库”,而是一整片生态。
2.6 Ingestion:只负责“带进来 + 标准化上下文”,不负责解释业务
在 EAM SaaS 数据平台中,Ingestion 层只解决一件事:
把数据可靠地带进来,并附上统一的上下文标签。
这一层的目标非常克制,但也非常关键:
- 数据必须进得来:接入稳定、链路可靠
- 数据必须可追踪:可以审计、可以排错
- 数据必须可隔离:多租户边界清晰
- 数据必须可重放:随时可以回溯与重算
因此,无论数据来自实时设备还是批量系统,进入平台时都会统一附加一组基础元数据,例如:
tenant_id:租户隔离与成本归因的根source:来源系统、协议或连接器标识ingest_time:数据进入平台的时间,而非业务发生时间trace_id:用于跨层追踪与链路审计
这些字段不表达业务语义,但表达了数据的“身份”与“上下文”。
2.6.1 两条接入通道:Real-time Events 与 Raw Batch Files
在 EAM SaaS 中,Ingestion 会将数据拆分进入两条不同的通道。
A) 实时数据:Real-time Events
对于 IoT 与传感器事件,我们通过 IoT Core + Python Connector 将其接入到实时事件通道,保证:
- 数据以事件流形式进入平台
- 可以被 Streaming Layer 解耦消费
- 每条事件都带着统一的上下文元数据
B) 批量数据:Raw Batch Files
对于传统业务系统(如 SAP、业务数据库 CDC、REST API 拉取等),我们通过 ETL Pipeline / AWS DMS 等方式生成 Raw Batch Files 并写入 Landing 区,保证:
- 数据以“不可变文件”的方式落地
- 能够被 Lake/Warehouse 重算与审计
- 不把业务逻辑塞进接入层
2.6.2 Ingestion 的关键原则:不解释业务含义
Ingestion 层必须刻意保持克制:
- 不做业务语义转换(例如状态映射、业务口径修正)
- 不计算指标(例如 MTBF、OEE、Availability)
- 不做跨源 Join(例如设备表 + 工单表 + 备件表拼接)
原因很简单:
接入层越“聪明”,系统越不可控;语义越早出现,分裂也会越早发生。
语义应该由 Warehouse 统一建模,而不是由每一个 connector “各自理解”。
2.7 工业 IoT 的特殊点:为什么 Ingestion 必须做 asset/tag 映射
不过,在工业物联网场景下,单纯只附加通用元数据还不够。
现实情况是,设备上传的点位标识往往与协议、厂商、项目强绑定,例如:
- MQTT topic:
factory/line1/motorA/vibration - OPC-UA NodeId:
ns=2;s=Channel1.Device3.Tag99 - Historian tag:
PUMP_01_TEMP_PV - 自定义 sensor code:
S-39201-AXX
这些标识可以唯一定位某一个“测点”,但它们并不等价于平台统一的资产语义。如果 downstream 想按资产维度查询相关测点,必须先解决两个问题:
- 这条 telemetry 属于哪台设备(
asset_id)? - 这是该设备上的哪个测点(
tag_id)?
因此,我们会在 Ingestion 阶段执行一层基础映射处理:
- 从原始 sensor code / topic / OPC-UA NodeId 中解析点位标识
- 将点位标识映射为平台统一的
tag_id - 同时绑定标准化的
asset_id
2.7.1 这个映射不是“业务语义解释”,而是“可对齐性工程”
这里必须强调:
这不是在接入层“建模”,更不是在接入层“算指标”。
它的作用,只是为后续所有处理建立统一的引用坐标系。
它解决的是工业数据里最现实、也最容易被低估的问题:
- 不同协议有不同命名体系
- 同一个点位在不同系统中可能有不同名字
- 同一个资产在不同厂区、不同项目里可能有不同编码
如果没有这层基础映射,下游通常会发生以下问题:
- 时间序列无法与资产主数据对齐
- 同一设备的信号被误当成多个设备
- 查询只能依赖“猜 topic/tag 名称”
- AI 特征无法稳定复用,训练与推理无法保持一致
换句话说:
你可以在 Warehouse 层再统一口径,但你必须在 Ingestion 层先统一“身份”。
2.7.2 建议的映射产物(落地视角)
在工程实现上,我们通常会沉淀两类产物(这里只强调概念,不展开到 Part 03)。
A) 映射表(Mapping Table / Registry)
用于将“外部标识”映射到“平台统一标识”:
source_type(mqtt / opcua / historian / …)source_identifier(topic / nodeId / tag_name / …)asset_idtag_ideffective_from/effective_to(支持设备改造、点位迁移)version(支持变更审计)
B) 事件上的标准字段(Normalized Event Envelope)
每条实时事件在进入 Streaming 前,至少应具备以下字段:
tenant_idasset_idtag_idevent_time(设备时间 / 采集时间)ingest_time(平台进入时间)valuequality(可选)
类似于下面的 JSON 结构:
1 | { |
有了这层标准化事件封装,downstream 就不再需要理解底层协议差异,也能以统一方式消费工业实时数据。
2.8 小结:六层架构的目的,是让系统“增长而不失控”
把 EAM SaaS 的数据平台拆分为六层,本质上是在做一件事:
用边界控制复杂度。
当系统规模扩大时,分层不是形式主义,而是生存条件。
- 没有 Ingestion 的克制,就没有语义一致性
- 没有 Streaming 的解耦,就没有实时链路的稳定性
- 没有 Lake 的不可变历史,就没有可回放与可审计能力
- 没有 Warehouse 的统一建模,就没有指标口径与可解释性
- 没有 Serving 的可控交付,就没有成本、权限与对外 SLA
- 没有 AI 对语义层的依赖,就没有可复现的预测与决策
工业 5.0 时代的 EAM 平台,如果要成为真正的“认知系统”,前提一定是:先成为一个数据秩序系统。
其他文章
